Visual Learning and Recognition
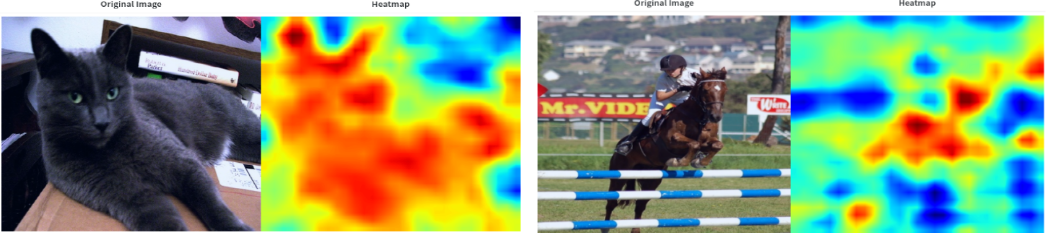
Weakly Supervised Object Localization
Implements a weakly supervised object detector which utilizes only image-level annotations and no bounding box annotations on the PASCAL VOC 2007 dataset.

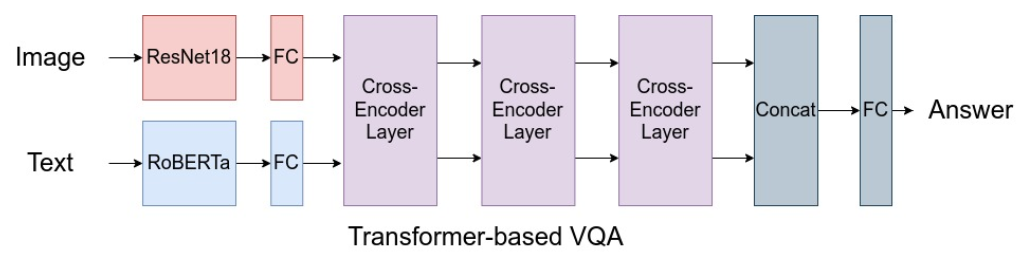
Visual Question Answering
In Visual Question Answering (VQA), given an image and a question about it, our goal is to select an answer from a large pool of possible answers. We implement a transformer based architecture which uses pre-trained ResNet18 and RoBERTa to featurize input images and text.

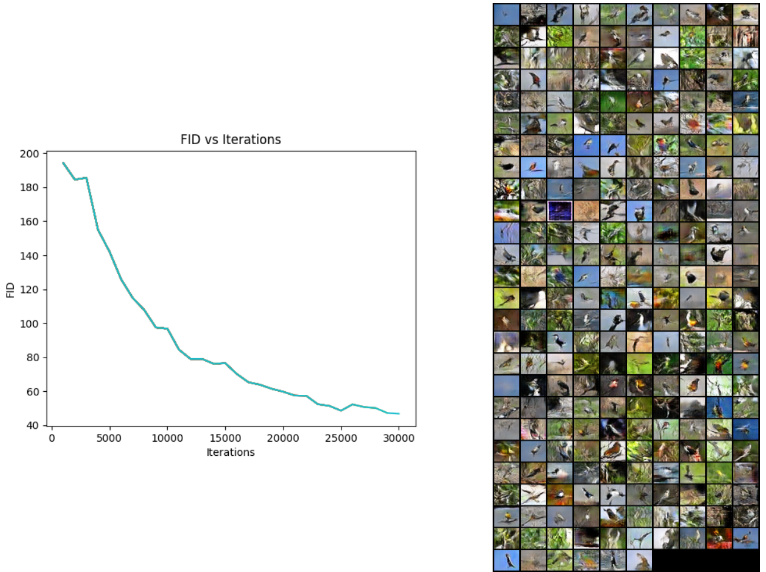
Generative Adversarial Networks
Trained GAN’s with various losses on the CUB 2011 Dataset to generate realistic-looking samples of these birds.
Vanilla GAN
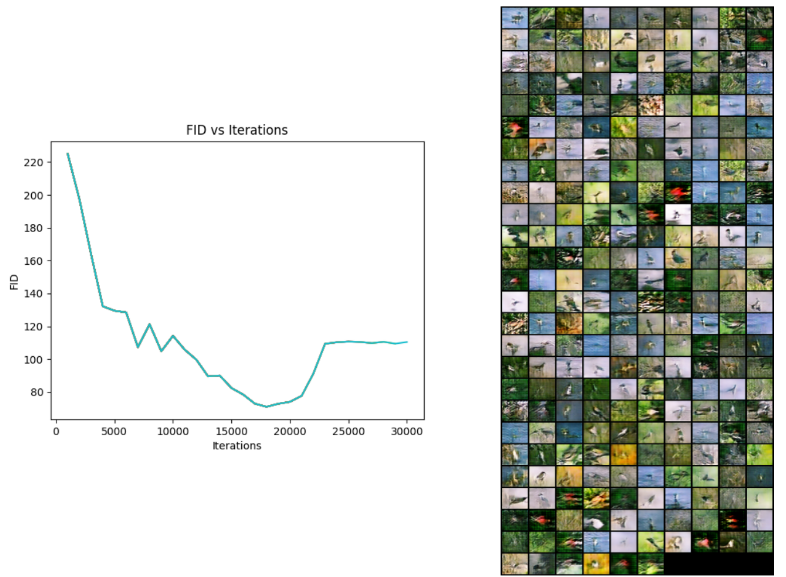
Least Squares GAN
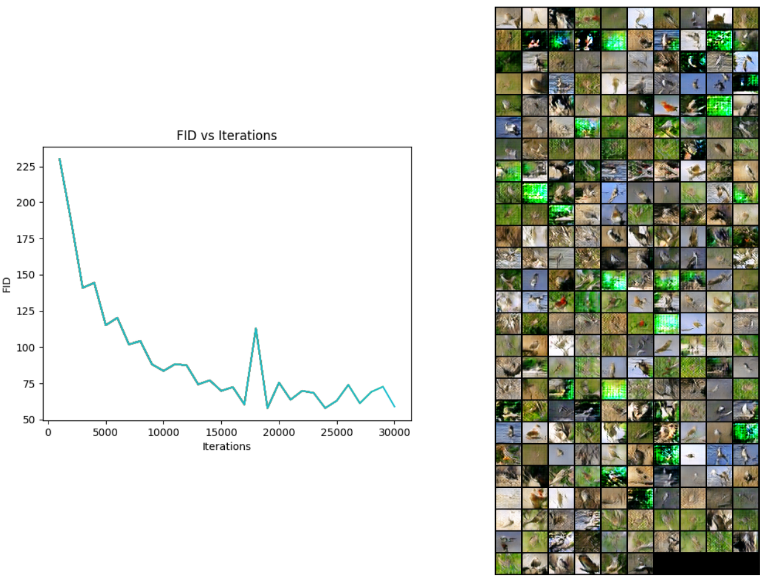
Wassertein GAN with Gradient Penalty